This workbook is an introduction to the basic concepts and designs relating to the paper
Fast estimation of sparse quantum noise by Harper, Yu and Flammia
This workbook is going to go through the basic ideas behind experimental design for a trivial 6 qubit system.
Initial things to note about the example¶
This is of marginal utility of only a 6 qubit system! There are only 4096 Paulis to measure in a 6 qubit system. The protocol requires a minimum number of 4n+2 experiments, each measuring (2^6) 64 possible outcomes. 2664 = 1664 measurements - we can reconstruct all the Paulis for not much more than this! For this type of protocol we are assuming a $\delta$ of about $0.25$, ie $4^{0.256}$, so we are expecting that we will only be seeking to recover the 8-9 highest weight Paulis - obviously as system size increases that is where the algorithm shines. So for instance with the 14 qubit example, in a later workbook - it makes a lot more sense.
Warning: As mentioned above this is a long and tedious workbook that is, ulitmately, in some sense disappointing. Because we simulate the entire experiment we can (and do) look at all the intermediate results. Six qubits takes about a minute to simulate a run, and we need to do 4*6+2 of them. At then end we get 8 (well often closer to 12) numbers that are *approximately* correct. I'll try and include a qiskit simulation, which will have a less realistic noise model - but will be more qubits. Then, of course, there is the work book which was used for the paper, it is based off actual 14 qubit experimental data and recovers a lot more information (because it is a bigger system). But if you want the whole gory detail, the system here is small enough to grasp everything that is happening but big enough to be not entirely trivial, although it's a lot of work for very little (because of the small size of the system).
Assumed knowledge¶
The workbook assumes some familiarity with the basic decoder, which is detailed in the workbook Scalabale Estimate - Basic Concepts. Another starter workbook that might be useful is Hadamard Basics and Observations - which also goes through the Hadamard transform (there is some duplication) but then shows how it fits in with the SuperOperator representation, the impact of only being able to measure commuting Paulis (in the one experiment) and how that relates to the circuits we design and the measurements we make. We will be using these concepts in the circuits we simulate here, and I probably won't go through it again here.
Because we are simulating the experiments here it is a bit painful - but I wanted to have an exact noise model so we could check we were in fact recovering what we expectes.
The other workbook released with the code will show how the algorithm performs in practice with data derived from an IBM Quantum Experience 14 qubit machine.
This is the place to start if you want to understand how the local stabiliser circuits are formed and the various decoding bins collated.¶
I have left volumes and volumes of data in the cells. If you are trying to debug your own decoder - that will be helpful.
Software needed¶
For this introductory notebook, we need minimal software. All these packages should be available through the Julia package manager. However, we will need some to help with the simulation etc.
If you get an error trying to "use" them the error message tells you how to load them.
using Hadamard
using PyPlot
# convenience (type /otimes<tab>) - <tab> is the "tab" key.
⊗ = kron
# type /oplus<tab>
⊕ = (x,y)->mod.(x+y,2)
# I love this add on, especially as some of the simulations take a noticeable time.
using ProgressMeter
# We are going to need some more of my code
# You can get it by doing the following, in the main julia repl (hit ']' to get to the package manager)
# pkg> add https://github.com/rharper2/Juqst.jl
# Currently there is harmless warning re overloading Hadamard.
using Juqst
# This is the code in this github that implements the various peeling algorithms for us.
include("peel.jl")
using Main.PEEL
Conventions¶
What's in a name?¶
There are a number of conventions as to where which qubit should be. Here we are going to adopt a least significant digit approach - which is different from the normal 'ket' approach.
So for example: IZ means and I 'Pauli' on qubit = 2 and a Z 'Pauli' on qubit = 1 (indexing off 1).
Arrays indexed starting with 1.¶
For those less familiar with Julia, unlike - say - python all arrays and vectors are indexed off 1. Without going into the merits or otherwise of this, we just need to keep it in mind. With our bitstring the bitstring 0000 represents the two qubits II, it has value 0, but it will index the first value in our vector i.e. 1.
Representing Paulis with bitstrings.¶
There are many ways to represent Paulis with bit strings, including for instance the convention used in Improved Simulation of Stabilizer Circuits, Scott Aaronson and Daniel Gottesman, arXiv:quant-ph/0406196v5.
Here we are going to use one that allows us to naturally translate the Pauli to its position in our vector of Pauli eigenvalues (of course this is arbitrary, we could map them however we like).
The mapping I am going to use is this (together with the least significant convention):
- I $\rightarrow$ 00
- X $\rightarrow$ 01
- Y $\rightarrow$ 10
- Z $\rightarrow$ 11
This then naturally translates as below:
SuperOperator - Pauli basis¶
We have defined our SuperOperator basis to be as below, which means with the julia vector starting at 1 we have :
| Pauli | Vector Index | --- | Binary | Integer |
|---|---|---|---|---|
| II | 1 | → | 0000 | 0 |
| IX | 2 | → | 0001 | 1 |
| IY | 3 | → | 0010 | 2 |
| IZ | 4 | → | 0011 | 3 |
| XI | 5 | → | 0100 | 4 |
| XX | 6 | → | 0101 | 5 |
| XY | 7 | → | 0110 | 6 |
| XZ | 8 | → | 0111 | 7 |
| YI | 9 | → | 1000 | 8 |
| YX | 10 | → | 1001 | 9 |
| YY | 11 | → | 1010 | 10 |
| YZ | 12 | → | 1011 | 11 |
| ZI | 13 | → | 1100 | 12 |
| ZX | 14 | → | 1101 | 13 |
| ZY | 15 | → | 1110 | 14 |
| ZZ | 16 | → | 1111 | 15 |
I have set this out in painful detail, because its important to understand the mapping for the rest to make sense.
So for instance in our EIGENVALUE vector (think superoperator diagonal), the PAUL YX has binary representation Y=10 X=01, therefore 1001, has "binary-value" 9 and is the 10th (9+1) entry in our eigenvalue vector.
What's in a Walsh Hadamard Transform?¶
The standard Walsh-Hadmard transform is based off tensor (Kronecker) products of the following matrix:
$$\left(\begin{array}{cc}1 & 1\\1 & -1\end{array}\right)^{\otimes n}$$WHT_natural¶
So for one qubit it would be:
$\begin{array}{cc} & \begin{array}{cccc} \quad 00 & \quad 01 & \quad 10 &\quad 11 \end{array}\\ \begin{array}{c} 00\\ 01\\ 10\\11\end{array} & \left(\begin{array}{cccc} \quad 1&\quad 1& \quad 1 &\quad 1\\ \quad 1 &\quad -1 & \quad 1 &\quad -1\\ \quad 1&\quad 1 & \quad -1 &\quad -1\\ \quad 1 &\quad -1 & \quad -1 &\quad 1\\\end{array}\right) \end{array}$
where I have included above (and to the left) of the transform matrix the binary representations of the position and the matrix can also be calculated as $(-1)^{\langle i,j\rangle}$ where the inner product here is the binary inner product $i,j\in\mathbb{F}_2^n$ as $\langle i,j\rangle=\sum^{n-1}_{t=0}i[t]j[t]$ with arithmetic over $\mathbb{F}_2$
WHT_Pauli¶
In the paper we use a different form of the Walsh-Hadamard transform. In this case we use the inner product of the Paulis, not the 'binary bitstring' inner product. The matrix is subtly different some rows or, if you prefer, columns are swapped:
$\begin{array}{cc} & \begin{array}{cccc} I(00) & X(01) & Y(10) & Z(11) \end{array}\\ \begin{array}{c} I(00)\\ X(01)\\ Y(10)\\Z(11)\end{array} & \left(\begin{array}{cccc} \quad 1&\quad 1& \quad 1 &\quad 1\\ \quad 1 &\quad 1 & \quad -1 &\quad -1\\ \quad 1&\quad -1 & \quad 1 &\quad -1\\ \quad 1 &\quad -1 & \quad -1 &\quad 1\\\end{array}\right) \end{array}$
Which one to use¶
When transforming Pauli eigenvalue to the probability of a particular error occuring, there are distinct advantages in using the WHT_Pauli transform. The order of the Pauli errors and the order of the Pauli eigenvalues remains the same. However, most common packages (including the one we are going to use here in Julia) don't support this type of transform, rather they implement the WHT_natural transform. The WHT_natural transform also makes the peeling algorithm slightly less fiddly. However it does mean we need to be very careful about the order of things. If we use the WHT_natural transform then the following relationship holds - note the indices (labels) of the Paulis in the probability vector:
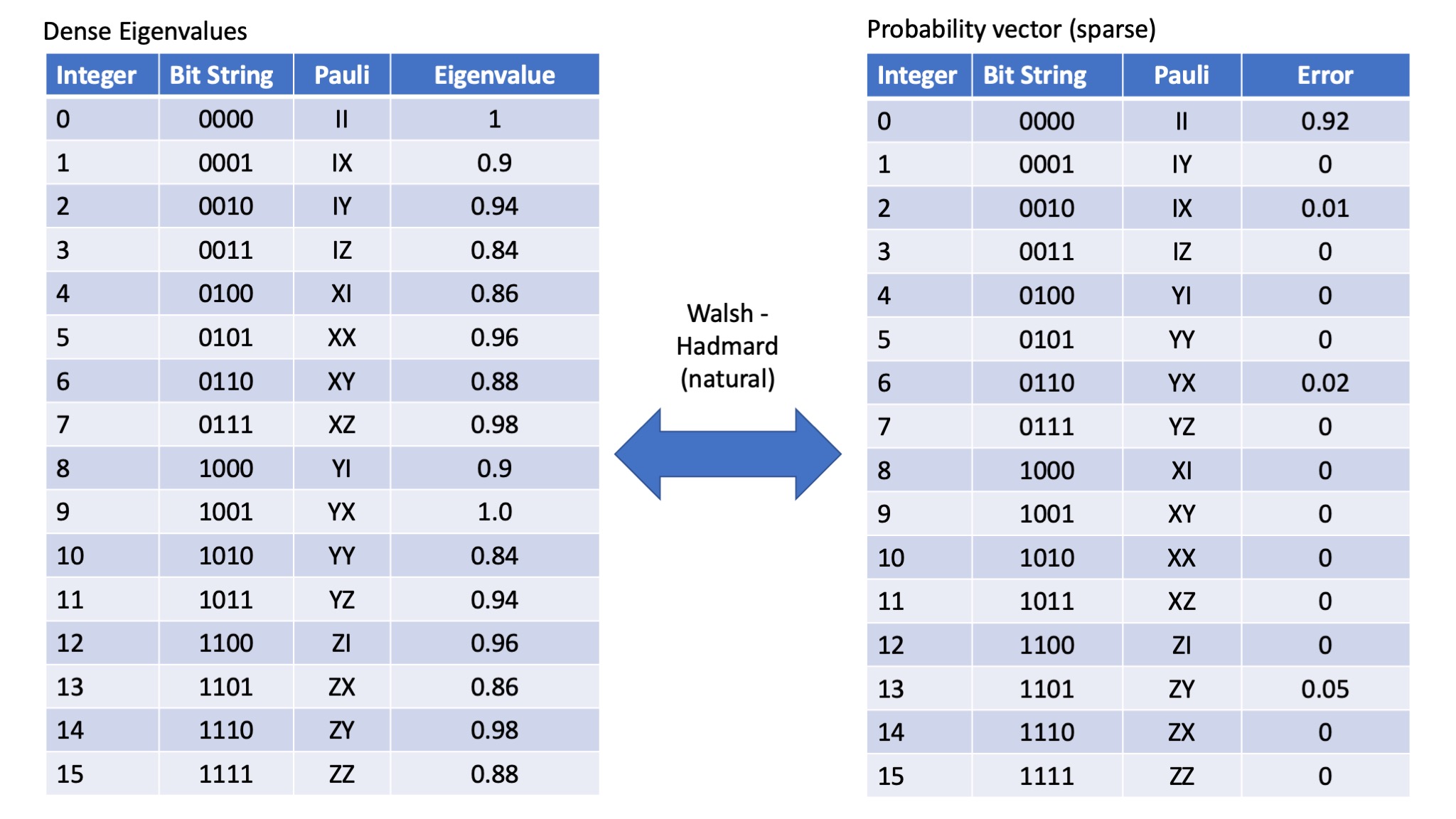
So the natural translation (labelling of Paulis) then becomes as follows:
Eigenvalue vector space¶
- I $\rightarrow$ 00
- X $\rightarrow$ 01
- Y $\rightarrow$ 10
- Z $\rightarrow$ 11
Probability vector space¶
- I $\rightarrow$ 00
- X $\rightarrow$ 10
- Y $\rightarrow$ 01
- Z $\rightarrow$ 11
The numbers above are the numbers we are going used in the "Basic concepts" workbook - here we are going to set up some more general errors
Set up some Pauli Errors to find¶
# Some functions to give us labels:
function probabilityLabels(x;qubits=2)
str = string(x,base=4,pad=qubits)
paulis = ['I','Y','X','Z']
return map(x->paulis[parse(Int,x)+1],str)
end
function fidelityLabels(x;qubits=2)
str = string(x,base=4,pad=qubits)
paulis = ['I','X','Y','Z']
return map(x->paulis[parse(Int,x)+1],str)
end
# To demonstrate the peeling decoder we are going to set up a sparse (fake) distribution.
# This is going to be a 4 qubit (so 4^6 = 4096 possible probabilities)
# Because of the protocol - we are assuming SPARSE errors - so most of the qubits
# Will be good, but there will be a few errors for us to find.
dist = zeros(4096)
cl = zeros(6,4)
# Qubit 1
cl[1,2] = 0.01 #y1
cl[1,3] = 0.004 #x1
cl[1,4] = 0 #z1
cl[1,1] = 1-sum(cl[1,:])
# Qubit 2
cl[2,2] = 0.0003
cl[2,3] = 0.0001
cl[2,4]= 0
cl[2,1] = 1-sum(cl[2,:])
# Qubit 3
cl[3,2] = 0.0002
cl[3,3] = 0.0001
cl[3,4] = 0.0003
cl[3,1] = 1-sum(cl[3,:])
# Qubit 4
cl[4,2] = 1e-4
cl[4,3] = 3e-4
cl[4,4] = 0
cl[4,1] = 1-sum(cl[4,:])
# Qubit 5
cl[5,2] = 0.004
cl[5,3] = 0.02
cl[5,4] = 0 #z1
cl[5,1] = 1-sum(cl[5,:])
# Qubit 6
cl[6,2] = 1e-4
cl[6,3] = 3e-4
cl[6,4] = 0
cl[6,1] = 1-sum(cl[6,:])
for q1 in 1:4
for q2 in 1:4
for q3 in 1:4
for q4 in 1:4
for q5 in 1:4
for q6 in 1:4
dist[(q6-1)*4^5+(q5-1)*4^4+(q4-1)*4^3+(q3-1)*4^2+(q2-1)*4+q1] = cl[1,q1]*cl[2,q2]*cl[3,q3]*cl[4,q4]*cl[5,q5]*cl[6,q6]
end
end
end
end
end
end
dist[3*4^4+2*16+3*4+3+1]= 0.004 # <----- Add an unexpected IZIXZZ error!
dist[1] = 0
dist[1] = 1-sum(dist)
for i in [1e-4,1e-5,1e-6,1e-7]
print("Number greater than $i = $(count([x>i for x in dist]))\n")
end
print("\nThe Paulis errors we might hope to recover with this protocol:\n")
for (ix,i) in enumerate(dist)
if i > 0.0001
print("$(string(ix,pad=3)) $(probabilityLabels(ix-1,qubits=6)) $i\n")
end
end
title("Distribution of Pauli error rates")
yscale("log")
ylabel("Error Rate")
xlabel("Paulis indexed and sorted by error rate")
scatter(2:50,reverse(sort(dist))[2:50])
print("\n\nThe actual oracle i.e. the eigenvalues of the Pauli channel we are going to use.\n\n")
actualOracle = round.(ifwht_natural(dist),digits=10)

# So we can use our actual oracle to simulate an experiment, we can include some so we will
# Rather than simulate a whole lot of Pauli circuits, which would serve to diagonlise the noise
# I am going to take the simpler state of assuming we have a Pauli channel - the SPAM will
# Therefore just get added on to the end.
# Here I am just assuming a suitable 6 qubit, independent random noise channel for SPAM
rm = foldl(⊗,[randomFidelityNoise() for _ in 1:6])
print("Our random SPAM channel has fidelity $(fidelity(rm)) and unitarity $(unitarity(rm))\n")
# Our noise channel is a Pauli channel, so just diagonalise our eigenvalue vector
using LinearAlgebra
noise = diagm(0=>actualOracle);
# So we have everything we need, we have SPAM channels and the 'diagonal' channel we would get if we
# averaged over Paulis.
So Let's get started!¶
Remember the point here is that the eigenvalues are dense, the pauli error rates are sparse. However, we can't sample the Pauli error rates in a SPAM (state preperation and measurement) error free way. We CAN however sample the eigenvalues in a SPAM free way. We wan't to sparsely sample the dense eigenvalues in order to reconstruct the sparse error probabilities.
This shows how to do this.
Choose our sub-sampling matrices¶
One of the main ideas behind the papers is that we can use the protocols in Efficient learning of quantum channels and Efficient learning of quantum noise to learn the eigenvalues of an entire stabiliser group ($2^n$) entries at once to arbitrary precision. Whilst it might be quite difficult to learn the eigenvalues of an arbitrary group as this will require an arbitrary $n-$qubit Clifford gate (which can be a lot of primitive gates!) even today's noisy devices can quite easily create a 2-local Stabiliser group over $n-$ qubits.
Finally we are simulating the recovery in a 6 qubit system. That means our bitstrings are 12 bits long.
Our experiments will need two sub-sampling groups. The first subsampling group will be two of our potential MuBs (set out below) (selected randomly). The second subsampling group will have single MUBs (potentialSingles below) on the first and fourth qubit, and a potential (two qubit) MuB on qubits 2 and 3.
This maximises the seperation of Paulis using local stabiliser (two qubit) groups.
potentialSingles = [
[[0,0],[0,1]], # IX
[[0,0],[1,0]], # IY
[[0,0],[1,1]], # IZ
]
all2QlMuBs = [ [[0,0,0,0],[1,1,0,1],[1,0,1,1],[0,1,1,0]], #II ZX YZ XY
[[0,0,0,0],[1,1,1,0],[0,1,1,1],[1,0,0,1]], #II ZY XZ YX
[[0,0,0,0],[0,0,0,1],[0,1,0,0],[0,1,0,1]], #II IX XI XX
[[0,0,0,0],[0,0,1,0],[1,0,0,0],[1,0,1,0]], #II IY YI YY
[[0,0,0,0],[0,0,1,1],[1,1,0,0],[1,1,1,1]]] #II IZ ZI ZZ
# We only want to choose the first two types for the initial runs
potentialMuBs = [all2QlMuBs[1],all2QlMuBs[2]]
paulisAll=[]
mappings=[]
experiments = []
# For this example I am just going to choose the second type of MUB.
# For six qubits we need three "potentialMuB"
for i = 1:1
push!(mappings,Dict())
choose = rand(1:2,3)
push!(experiments,vcat([(2,choose[1])],[(2,choose[2])],[(2,choose[3])]))
push!(paulisAll,vcat([potentialMuBs[x] for x in choose]))
end
# For the next subsample group, choose a single, two doubles and a single.
for i = 1:1
push!(mappings,Dict())
chooseS = rand(1:3,2)
choose = rand(1:2,2)
push!(experiments,vcat([(1,chooseS[1])],[(2,choose[1])],[(2,choose[2])],[(1,chooseS[2])]))
push!(paulisAll,vcat([potentialSingles[chooseS[1]]],[potentialMuBs[x] for x in choose],[potentialSingles[chooseS[2]]]))
end
# Create the 'bit' offsets
# This is used to work out the Pauli we isolate in a single bin. Here we have 2*(n=2), 4 bits per Pauli
ds = vcat(
[[0 for _ = 1:12]],
[map(x->parse(Int,x),collect(reverse(string(i,base=2,pad=12)))) for i in [2^b for b=0:11]]);
# e.g.
print("For the offsets we are using the simplest method for Pauli identification eg:\n")
for (ix,i) in enumerate(ds)
print("Offset $(ix-1): $i\n")
end
print("\n\nWe have selected two sub-sampling groups. \n\nThe first is two randomly selected 'two quibt' mubs on the qubits:\n")
print("Qubits 1&2: $(paulisAll[1][1])\n")
print("Qubits 3&4: $(paulisAll[1][2])\n")
print("Qubits 5&6: $(paulisAll[1][3])\n\n")
print("\n\nThe second, we want to offset by 1 qubit, so we have single qubit mubs on qubit 1, a two qubit mub on 2&3 and 4&5 and then we need a single qubit mub on qubit 6.\n")
print("Qubit 1 : $(paulisAll[2][1])\n")
print("Qubits 2&3: $(paulisAll[2][2])\n")
print("Qubits 2&3: $(paulisAll[2][3])\n")
print("Qubit 4. : $(paulisAll[2][4])\n")
# Here there are two sets of experiments
# The tuple for each qubit, is the (number, experiment type),
# the numbers for each will add up to 4 (since we have 4 qubits)
experiments
The Experiments¶
So what are these experiments?¶
Let's pull in the figure from the paper which shows all the experimental designs:
Okay that's a bit busy, lets break it down.
Step 1 was to choose one MUB from the set for each pair of qubits, well that is what we did in PaulisAll, lets look at the first element of that
paulisAll[1]
So because it was randomly chosen, you will have to look at that and convince yourself that indeed that each of the two elements shown above are one of these four sets of MuBs.
So the first experiment (the top row of (2)) is just an experiment to extract those eigenvalues.
How do we do that?
Well we have the circuits we need in the appendix of the paper - they look like this:

Where what we are going to need on each two qubit pair is either (a) or (c), depending on the MUB randomly selected
Setting up the circuits¶
For the two qubit expermeints, circuit 1 is (a) above and circuit (2) is (c) above.
Effectively we take an input state in the computational basis, apply these circuits, do a Pauli twirl of varing gates, reverse the circuit and measure in the computational basis.
To simulate this I am just going to set up the circuits as a superoperator. The way rb Pauli twirling works, the noise will be subsumed into the SPAM error - which we will then fit out, but I am getting ahead of myself.
Let's create the superoperator that does (a) and (c) on two qubits:
For a more detailed explanation of what I am doing in the next cell, look at the Hadamard Basics and Observations workbook
using Juqst
# Set up the relevant gates
cnot21 = [1 0;0 1]⊗[1 0;0 0]+ [0 1;1 0]⊗[0 0;0 1]
superCnot21 = makeSuper(cnot21)
superPI = makeSuper([1 0;0 im]⊗[1 0;0 1])
superIP = makeSuper([1 0;0 1]⊗[1 0;0 im])
superHH = makeSuper((1/sqrt(2)*[1 1;1 -1])⊗(1/sqrt(2)*[1 1;1 -1]));
superH = makeSuper((1/sqrt(2)*[1 1;1 -1]))
superP = makeSuper([1 0;0 im])
# The two qubit experiment are (a) and (b) above
# Recall circuits are left to right, matrices right to left
circuit2q = [superCnot21*superPI*superCnot21*superIP*superHH,
superCnot21*superPI*superCnot21*superPI*superHH]
# The single qubit ones are Paulis, X,Y,Z
circuit1q = [superH,superP*superH,makeSuper([1 0;0 1])];
So the first experiment is as shown in the above diagram ... this bit:

where our C's (left hand side of that diagram - which I have just noticed is (irritatingly) right to left (you can tell from the |0> on the right). Each of the circuits 2q calculated above represents one of our two choices of Mubs, we would then twirl with Paulis, average over lots of different twirls (to diagonalise it) and then reverse out and measure.
I am NOT going to simulate the Pauli twirl, but rather I am just going to use the (already) diagonal noise matrix we calculated earlier. The noisy circuits2q and state and measurement errors will be simulated by using the measurement (SPAM) noise matrix formed earlier.
(I probably will do the whole thing in a qiskit simulation)
# So the circuits we want are shown here
experiments[1]
function generateGates(experiment,circuits)
# We expect the gates as a tuple, i.e. (a,b) where a is number of qubits and b is the experiment number
# circuits is a an array of size upto number of qubits, so circuits[a][b] returns an "a" qubit experiment
# we can then use foldl to kron up the circuits
return foldl(⊗, [circuits[x[1]][x[2]] for x in reverse(experiment)])
end
# Simplify the code here, we know its two qubits:
# Note the order of the \kron - obviously with an experiment you just set up the actual experiment!
# You can think of generateGates, doing the equivalent of the following
#initialGates = circuit2q[experiments[1][3][2]]⊗circuit2q[experiments[1][2][2]]⊗circuit2q[experiments[1][1][2]]
initialGates = generateGates(experiments[1],[circuit1q,circuit2q])
reverseGates = transpose(initialGates); # yay superoperators.
# So there is a bit of delay here, mainly its the genZs which isn't the most efficient, but we only do it once.
# We can generate the computational basis measurment vectors (again see Hadamard Basics and Observations for details)
zs = Juqst.genZs(6);
start = zs[1]; #computational basis all 0 state
Faking (simulating) the experiment¶
In theory we could put this in qiskit or cirq or something - but here I want to simulate a very specific noise channel to show we can recover it, and these simulators only allow more general noise (at the time of writing this).
So the basic concept is:
- we start with the computational basis vector,
- we apply our SPAM
- we apply our basis change circuit (initial Gates)
- we apply our diagonal noise $m$ times (this is the noise we want to measure - see below for choice of $m$)
- we undo our basis change
- we find our final probability vector (for observed errors in this basis) (basically each of the measurment arrays we generates - the zs)
- then we face a whole lot of random dice rolls to build up some limited shot statistics.
Finally repeat all the above for different values of $m$. Here we are just going to use m = 1,3,5,8,10,15,20,40,60,80
experiment1_allProbs = []
# These will depend on your system
lengths = [1,3,5,8,10,15,20,40,60,80]
@showprogress for m in lengths
wholeCircuit = reverseGates*noise^m*initialGates*rm*start./64 # ./64 = Normalise the measurement/state vectors
probs = [z'*wholeCircuit for z in zs]
push!(experiment1_allProbs,probs)
end
# SO NOTE that although there are 4096 eigenvalues, we can only measure 64 of them at a time,
# so the probability matrices are only 64 long.
# Quick Sanity check that all of our probabilityvectors sum to 1
for (ix,i) in enumerate(experiment1_allProbs)
print("M=$(lengths[ix]) sum = $(round(sum(i),digits=9))\n")
end
# So the final step, now that we have the probability matrix for that experiment, is to simulate limited shot statistics.
# So if we imagined doing 100 sequences, of 200 measurements per seq thats 20,000 shots.
const shotsToDo = 20000
# Quick helper function
function shotSimulator(size,shots,cumulativeMatrix)
toRet = []
for todo = 1:length(cumulativeMatrix)
counted = zeros(size)
rolls = rand(shots)
for i in rolls
#using the fact that the cululativeMatrix is (effectively) sorted.
counted[searchsortedfirst(cumulativeMatrix[todo],i,)] +=1
end
push!(toRet,counted./shots)
end
return toRet
end
# We need culmlative probability matrixes
cumMatrix = map(cumsum,experiment1_allProbs)
experiment1_observed = shotSimulator(64,shotsToDo,cumMatrix);
The next step is to recreate the eigenvalues that we have 'measured' in the experiment.¶
This is just following the protocol in https://arxiv.org/abs/1907.13022, Efficient Learning of Quantum Noise (and https://arxiv.org/abs/1907.12976 Efficient Estimation of Pauli Channels)
We want to Hadamard transform the observed Probabilities¶
if we do that we will see for each eigenvalue (element in the matrix) an exponential decay curve - lets look
experiment1_SpamyEigenvalues = map(ifwht_natural,experiment1_observed);
# Dont bother with the first element as its all 1.
for x = 2:64
toPlot = [d[x] for d in experiment1_SpamyEigenvalues]
plot(lengths,toPlot)
end

So fit and extract¶
What we want to do is fit them to and exponential decay curve and extract the decay factor. Juqst has the code for this, and you are welcome to look at the documentation and example notebooks for that!
For those that can't be bothered reading docs! fitTheFidelites returns params that contains both the SPAM component and the fidelity - the second parameter is the number of measurements used in the fit and the last is if any of the fits failed. We just want to extract the eigenvalues:
(params,l, failed) = fitTheFidelities(lengths,experiment1_observed)
experiment1_fidelities = vcat(1,[p[2] for p in params]) # We don't fit the first one, it is always 1 for CPTP maps
So what did we actually extract?¶
Note this bit is kind of fidly - to get everything to match up
Well we extracted certain fidelities!
The four fidelities on the first qubit were:
paulisAll[1][1]
paulisAll[1][2]
#Turn those into a number...
fidelitiesExtracted = []
function binaryArrayToNumber(x)
return foldl((y1,y2)->y1<<1+y2,x)
end
for x0 in paulisAll[1][3]
p56 = binaryArrayToNumber(x0)
for x1 in paulisAll[1][2]
p34 = binaryArrayToNumber(x1)
for x2 in paulisAll[1][1]
p12= binaryArrayToNumber(x2)
push!(fidelitiesExtracted,p56*4^4+p34*16+p12+1) # + 1 cause we index of 1 in Julia
end
end
end
fidelitiesExtracted
xx = ifwht_natural([z'*reverseGates*noise*initialGates*start for z in zs]/64)
for p in xx
print("$p : $(findall(x->isapprox(x,p),actualOracle))\n")
end
# And (just out of interest we can compare the fidelities we extracted, with the actual values)
for i in 1:64
print("$(fidelityLabels(fidelitiesExtracted[i]-1,qubits=6)) ($(fidelitiesExtracted[i]-1)):\tEstimate: $(experiment1_fidelities[i]) <-> $(actualOracle[fidelitiesExtracted[i]]) \tPercentage Error: $(round.(abs(actualOracle[fidelitiesExtracted[i]]-experiment1_fidelities[i])/(actualOracle[fidelitiesExtracted[i]])*100,digits=4))%\n")
end
Not bad for 20,000 shots.¶
Building up our eigenvalue Oracle¶
So now we can begin to populate our estimating oracle that we will use to run the peeling decoder.
we have 16 values, lets fill them in...
# Lets make it a vector of vectors
# - why? Well some of the experiments will have duplicate eigenvalue estimates, and we will want
# To end up averaging them.
estimateOracle = [[] for _ in 1:4096]
for i in 1:64
push!(estimateOracle[fidelitiesExtracted[i]],experiment1_fidelities[i])
end
estimateOracle
# So I am going to just do all of the above for each of the 5 (other than the one already done) for each of the qubits
e1_all_additional_fidelities = []
e1_fidelity_extracted = []
# Note we don't actually need to save the actual probabilities - but I am going to use them later
# To demonstrate some different recovery regimes.
e1_all_actualProbabilities = []
e1_gatesUsed = []
@showprogress 1 "QubitPairs" for qubitPairOn = 1:2 # qubit pairs here are 1&2, 3&4 and 5&6
for experimentType = 1:2
if experiments[1][qubitPairOn][2] != experimentType
# Its one we haven't done
expOnFirstPair = experiments[1][1][2]
expOnSecondPair = experiments[1][2][2]
expOnThirdPair = experiments[1][3][2]
if qubitPairOn == 1
expOnFirstPair = experimentType
elseif qubitPairOn == 2
expOnSecondPair = experimentType
else
expOnThirdPair = experimentType
end
initialGates = circuit2q[expOnThirdPair]⊗circuit2q[expOnSecondPair]⊗circuit2q[expOnFirstPair]
push!(e1_gatesUsed,initialGates)
reverseGates = transpose(initialGates) # yay superoperators.
# So at this point we have set up one of the 'new' experiments.
additionalExperiment = []
# Get the actual probabilities.
@showprogress 1 "QGroup: $qubitPairOn Exp: $experimentType" for m in lengths
wholeCircuit = rm*reverseGates*noise^m*initialGates*start./64 # Normalising our zs
probs = [z'*wholeCircuit for z in zs]
push!(additionalExperiment,probs)
end
push!(e1_all_actualProbabilities,additionalExperiment)
# Generate the measurement statistics
cumMatrix = map(cumsum,additionalExperiment)
experiment1_additional_observed = shotSimulator(64,shotsToDo,cumMatrix);
# Fit and extract the fidelities
(params,l, failed) = fitTheFidelities(lengths,experiment1_additional_observed)
experiment1_additional_fidelities = vcat(1,[p[2] for p in params])
push!(e1_all_additional_fidelities,experiment1_additional_fidelities)
fidelitiesExtracted=[]
for x0 in all2QlMuBs[expOnThirdPair]
p56 = binaryArrayToNumber(x0)
for x1 in all2QlMuBs[expOnSecondPair]
p34 = binaryArrayToNumber(x1)
for x2 in all2QlMuBs[expOnFirstPair]
p12= binaryArrayToNumber(x2)
push!(fidelitiesExtracted,p56*4^4+p34*16+p12+1) # + 1 cause we index of 1 in Julia
end
end
end
push!(e1_fidelity_extracted,fidelitiesExtracted)
end
end
end
#initialGates = generateGates(experiments[1],[circuit1q,circuit2q])
expOnFirstPair = experiments[1][1][2]
expOnSecondPair = experiments[1][2][2]
expOnThirdPair = experiments[1][3][2]
print(expOnFirstPair,expOnSecondPair,expOnThirdPair)
initialGates = circuit2q[expOnThirdPair]⊗circuit2q[expOnSecondPair]⊗circuit2q[expOnFirstPair]
reverseGates = transpose(initialGates); # yay superoperators.
experiment1_allProbs = []
# These will depend on your system
lengths = [1,3,5,8,10,15,20,40,60,80]
@showprogress for m in lengths
wholeCircuit = reverseGates*noise^m*initialGates*rm*start./64 # ./64 = Normalise the measurement/state vectors
probs = [z'*wholeCircuit for z in zs]
push!(experiment1_allProbs,probs)
end
# We need culmlative probability matrixes
cumMatrix = map(cumsum,experiment1_allProbs)
experiment1_observed = shotSimulator(64,shotsToDo,cumMatrix);
(params,l, failed) = fitTheFidelities(lengths,experiment1_observed)
experiment1_fidelities = vcat(1,[p[2] for p in params]) # We don't fit the first one, it is always 1 for CPTP maps
fidelitiesExtracted = []
function binaryArrayToNumber(x)
return foldl((y1,y2)->y1<<1+y2,x)
end
for x0 in all2QlMuBs[expOnThirdPair]
p56 = binaryArrayToNumber(x0)
for x1 in all2QlMuBs[expOnSecondPair]
p34 = binaryArrayToNumber(x1)
for x2 in all2QlMuBs[expOnFirstPair]
p12= binaryArrayToNumber(x2)
push!(fidelitiesExtracted,p56*4^4+p34*16+p12+1) # + 1 cause we index of 1 in Julia
end
end
end
# for x0 in paulisAll[1][3]
# p56 = binaryArrayToNumber(x0)
# for x1 in paulisAll[1][2]
# p34 = binaryArrayToNumber(x1)
# for x2 in paulisAll[1][1]
# p12= binaryArrayToNumber(x2)
# push!(fidelitiesExtracted,p56*4^4+p34*16+p12+1) # + 1 cause we index of 1 in Julia
# end
# end
# end
# And (just out of interest we can compare the fidelities we extracted, with the actual values)
for i in 1:64
print("$(fidelityLabels(fidelitiesExtracted[i]-1,qubits=6)) ($(fidelitiesExtracted[i]-1)):\tEstimate: $(experiment1_fidelities[i]) <-> $(actualOracle[fidelitiesExtracted[i]]) \tPercentage Error: $(round.(abs(actualOracle[fidelitiesExtracted[i]]-experiment1_fidelities[i])/(actualOracle[fidelitiesExtracted[i]])*100,digits=4))%\n")
end
So now we need to put into the oracle the offsets for this experiment we will need.¶
This is step 2 in the diagram from the paper (a long way back up there $\uparrow$.
Basically for each pair of qubits, we have to cycle through four of the two qubit mubs (there are five but we have done one already). That means we have another 8 experiments, i.e. 2n where n is the number of qubits. For each sub-sampling group we need to do 2n+1 experiments. Let's create the initial and reverse gates for each of the 3 Mubs we haven't already got ([II,IX,XI,XX], [II,IY,YI,YY], [II,IZ,ZI,ZZ]])
# We already had the first bit, repeating just to make the cell self-contained.
circuit2q = [superCnot21*superPI*superCnot21*superIP*superHH,
superCnot21*superPI*superCnot21*superPI*superHH]
push!(circuit2q,superHH) # The XX one
push!(circuit2q,superIP*superPI*superHH) # the YY one
push!(circuit2q,makeSuper([1 0;0 1]⊗[1 0;0 1])) # The ZZ one i.e. nothing.
# So I am going to just do all of the above for each of the 5 (other than the one already done) for each of the qubits
e1_all_additional_fidelities = []
e1_fidelity_extracted = []
# Note we don't actually need to save the actual probabilities - but I am going to use them later
# To demonstrate some different recovery regimes.
e1_all_actualProbabilities = []
@showprogress 1 "QubitPairs" for qubitPairOn = 1:3 # qubit pairs here are 1&2, 3&4 and 5&6
for experimentType = 1:5
if experiments[1][qubitPairOn][2] != experimentType
# Its one we haven't done
expOnFirstPair = experiments[1][1][2]
expOnSecondPair = experiments[1][2][2]
expOnThirdPair = experiments[1][3][2]
if qubitPairOn == 1
expOnFirstPair = experimentType
elseif qubitPairOn == 2
expOnSecondPair = experimentType
else
expOnThirdPair = experimentType
end
initialGates = circuit2q[expOnThirdPair]⊗circuit2q[expOnSecondPair]⊗circuit2q[expOnFirstPair]
reverseGates = transpose(initialGates) # yay superoperators.
# So at this point we have set up one of the 'new' experiments.
additionalExperiment = []
# Get the actual probabilities.
@showprogress 1 "QGroup: $qubitPairOn Exp: $experimentType" for m in lengths
wholeCircuit = reverseGates*noise^m*initialGates*rm*start./64 # Normalising our zs
probs = [z'*wholeCircuit for z in zs]
push!(additionalExperiment,probs)
end
push!(e1_all_actualProbabilities,additionalExperiment)
# Generate the measurement statistics
cumMatrix = map(cumsum,additionalExperiment)
experiment1_additional_observed = shotSimulator(64,shotsToDo,cumMatrix);
# Fit and extract the fidelities
(params,l, failed) = fitTheFidelities(lengths,experiment1_additional_observed)
experiment1_additional_fidelities = vcat(1,[p[2] for p in params])
push!(e1_all_additional_fidelities,experiment1_additional_fidelities)
fidelitiesExtracted=[]
for x0 in all2QlMuBs[expOnThirdPair]
p56 = binaryArrayToNumber(x0)
for x1 in all2QlMuBs[expOnSecondPair]
p34 = binaryArrayToNumber(x1)
for x2 in all2QlMuBs[expOnFirstPair]
p12= binaryArrayToNumber(x2)
push!(fidelitiesExtracted,p56*4^4+p34*16+p12+1) # + 1 cause we index of 1 in Julia
end
end
end
push!(e1_fidelity_extracted,fidelitiesExtracted)
end
end
end
# So for example, if we look at some of these additional 12 experiments, we see
# The following - look at the changing eigevalues we sample (left hand side).
# E.g. exerimpent 12 as qubits 5&6 with the the II IZ ZI ZZ stabiliser.
toExtract = 12
# And (just out of interest we can compare the fidelities we extracted, with the actual values)
for i in 1:64
print("$(fidelityLabels(e1_fidelity_extracted[toExtract][i]-1,qubits=6)) ",
"($(e1_fidelity_extracted[toExtract][i])): ",
"\tEstimate: $(round(e1_all_additional_fidelities[toExtract][i],digits=5))",
" <-> $(round(actualOracle[e1_fidelity_extracted[toExtract][i]],digits=5)) ",
"\tPercentage Error: $(round.(abs(actualOracle[e1_fidelity_extracted[toExtract][i]]-e1_all_additional_fidelities[toExtract][i])/(actualOracle[e1_fidelity_extracted[toExtract][i]])*100,digits=4))%\n")
end
# So we just need to fill in the oracle
for (expNo,x) in enumerate(e1_fidelity_extracted)
for (fidelityIndex,fidelity) in enumerate(x)
push!(estimateOracle[fidelity],e1_all_additional_fidelities[expNo][fidelityIndex])
end
end
# our oracle so far
for i in 1:4096
if estimateOracle[i]!=[]
print("$(string(i,pad=3)) $(round.(actualOracle[i],digits=5)) \t$(round.(estimateOracle[i],digits=5))\n")
end
end
e1_fidelity_extracted
experiments[2]
# So q1, has single qubit mub, q2&3 4&5 have a double mub experiment type 2 and q6 has a single mub, so lets set that up:
initialGates = generateGates(experiments[2],[circuit1q,circuit2q])
reverseGates = transpose(initialGates)
# So at this point we have set up one of the 'new' experiments.
experiment2 = []
# Get the actual probabilities.
@showprogress 1 "Lengths: " for m in lengths
wholeCircuit = reverseGates*noise^m*initialGates*rm*start./64 # Normalising our zs
probs = [z'*wholeCircuit for z in zs]
push!(experiment2,probs)
end
# Generate shot limited stats
cumMatrix = map(cumsum,experiment2)
experiment2_observed = shotSimulator(64,shotsToDo,cumMatrix);
# Fit and extract the fidelities
(params,l, failed) = fitTheFidelities(lengths,experiment2_observed)
experiment2_fidelities = vcat(1,[p[2] for p in params])
xx = ifwht_natural([z'*reverseGates*noise*initialGates*start for z in zs]/64)
for p in xx
print("$p : $(findall(x->isapprox(x,p),actualOracle))\n")
end
fidelitiesExtracted = []
for x1b in potentialSingles[experiments[2][4][2]] # Experiment 2, qubit division 3 (q1, q2&3, q4) the second part = exp number
p6 = binaryArrayToNumber(x1b)
for x2b in all2QlMuBs[experiments[2][3][2]]
p45 = binaryArrayToNumber(x2b)
for x2a in all2QlMuBs[experiments[2][2][2]]
p23 = binaryArrayToNumber(x2a)
for x1a in potentialSingles[experiments[2][1][2]]
p1 = binaryArrayToNumber(x1a)
push!(fidelitiesExtracted,p6*4^5+p45*4^3+p23*4^1+p1+1) # + 1 cause we index of 1 in Julia
end
end
end
end
map(x->fidelityLabels(x-1,qubits=6),fidelitiesExtracted)
# And (just out of interest we can compare the fidelities we extracted, with the actual values)
for i in 1:64
print("$(fidelityLabels(fidelitiesExtracted[i]-1,qubits=6)) ",
"($(fidelitiesExtracted[i]-1)):\tEstimate: $(experiment2_fidelities[i]) ",
"<-> $(actualOracle[fidelitiesExtracted[i]]) \t",
"Percentage Error: $(round.(abs(actualOracle[fidelitiesExtracted[i]]-experiment2_fidelities[i])/(actualOracle[fidelitiesExtracted[i]])*100,digits=4))%\n")
end
# Save you the sanity check and I will put these directly into the oracle
for (fidelityIndex,fidelity) in enumerate(fidelitiesExtracted)
push!(estimateOracle[fidelity],experiment2_fidelities[fidelityIndex])
end
# our oracle so far
for i in 1:4096
if estimateOracle[i]!=[]
print("$(string(i,pad=3)) $(round.(actualOracle[i],digits=5)) \t$(round.(estimateOracle[i],digits=5))\n")
end
end
And super finally we just need to create the offsets to get their fidelities.¶
For the single qubit Mubs, we need the other 2 mubs, for the two qubit Mubs the other four.
e2_all_additional_fidelities = []
e2_fidelity_extracted = []
# Note here I am hard coding that we have single qubit twirls on 1 and 4.
e_count = 0
e2_all_actualProbabilities = []
@showprogress 1 "Qubits: " for qubitOn in 1:4 # qubits we can be "On" here are 1, 2&3 4&5 and 6
if qubitOn == 2 || qubitOn == 3
noOfExperiments = 5
else
noOfExperiments = 3 # Only 3 if its a single qubit.
end
for experimentType = 1:noOfExperiments
if experiments[2][qubitOn][2] != experimentType
# Its one we haven't done
expOnFirstSet = experiments[2][1][2]
expOnSecondSet = experiments[2][2][2]
expOnThirdSet = experiments[2][3][2]
expOnFourthSet = experiments[2][4][2]
if qubitOn == 1
expOnFirstSet = experimentType
elseif qubitOn == 2
expOnSecondSet = experimentType
elseif qubitOn ==3
expOnThirdSet = experimentType
else
expOnFourthSet = experimentType
end
initialGates = circuit1q[expOnFourthSet]⊗circuit2q[expOnThirdSet]⊗circuit2q[expOnSecondSet]⊗circuit1q[expOnFirstSet]
reverseGates = transpose(initialGates) # yay superoperators.
# So at this point we have set up one of the 'new' experiments.
additionalExperiment = []
# Get the actual probabilities.
@showprogress 1 "QGroup $qubitOn Exp: $experimentType: " for m in lengths
wholeCircuit = reverseGates*noise^m*initialGates*rm*start./64 # Normalising our zs
probs = [z'*wholeCircuit for z in zs]
push!(additionalExperiment,probs)
end
push!(e2_all_actualProbabilities,additionalExperiment)
# Generate the measurement statistics
cumMatrix = map(cumsum,additionalExperiment)
experiment2_additional_observed = shotSimulator(64,shotsToDo,cumMatrix);
# Fit and extract the fidelities
(params,l, failed) = fitTheFidelities(lengths,experiment2_additional_observed)
experiment2_additional_fidelities = vcat(1,[p[2] for p in params])
push!(e2_all_additional_fidelities,experiment2_additional_fidelities)
fidelitiesExtracted=[]
for x1 in potentialSingles[expOnFourthSet] # Experiment 2, qubit division 3 (q1, q2&3, q4&5 q6) the second part = exp number
p6 = binaryArrayToNumber(x1)
for x2b in all2QlMuBs[expOnThirdSet]
p45 = binaryArrayToNumber(x2b)
for x2 in all2QlMuBs[expOnSecondSet]
p23 = binaryArrayToNumber(x2)
for x3 in potentialSingles[expOnFirstSet]
p1 = binaryArrayToNumber(x3)
push!(fidelitiesExtracted,p6*4^5+p45*4^3+p23*4+p1+1) # + 1 cause we index of 1 in Julia
end
end
end
end
push!(e2_fidelity_extracted,fidelitiesExtracted)
end
end
end
e2_all_additional_fidelities[1]
# So for example, if we look experiment 8 of these additional experiments, we see
toExtract = 8
# And (just out of interest we can compare the fidelities we extracted, with the actual values)
for i in 1:64
print("$(fidelityLabels(e2_fidelity_extracted[toExtract][i]-1,qubits=6)) ",
"($(e2_fidelity_extracted[toExtract][i])): ",
"\tEstimate: $(round(e2_all_additional_fidelities[toExtract][i],digits=5))",
" <-> $(round(actualOracle[e2_fidelity_extracted[toExtract][i]],digits=5)) ",
"\tPercentage Error: $(round.(abs(actualOracle[e2_fidelity_extracted[toExtract][i]]-e2_all_additional_fidelities[toExtract][i])/(actualOracle[e2_fidelity_extracted[toExtract][i]])*100,digits=4))%\n")
end
# Okay load them all up into the oracle
for (expNo,x) in enumerate(e2_fidelity_extracted)
for (fidelityIndex,fidelity) in enumerate(x)
push!(estimateOracle[fidelity],e2_all_additional_fidelities[expNo][fidelityIndex])
end
end
# our oracle so far
for i in 1:4096
if estimateOracle[i]!=[]
print("$(string(i,pad=3)) $(round.(actualOracle[i],digits=5)) \t$(round.(estimateOracle[i],digits=5))\n")
end
end
using Statistics
# So we can get an idea of the variance in the oracle (where we have fidelities)
# This is based off 1,000 shots per 'experiment sequence'
for (ix,i) in enumerate(estimateOracle)
if length(i) > 1
print("$ix: $(var(i))\n")
end
end
# Get our oracle single figure
oracleToUse = [length(x) > 0 ? mean(x) : 0 for x in estimateOracle]
# Just out of intereset we can now work out the error in the oracle using this number of shots and our
# fitting algorithm:
print("Actual error in the eigenvalues estimated\n")
avE =[]
for (ix,i) in enumerate(oracleToUse)
if i !=0
percentError = round((i-actualOracle[ix])/actualOracle[ix]*100,digits=6)
push!(avE,percentError)
print("$(string(ix,pad=4)): $(fidelityLabels(ix-1,qubits=6)): $(round(percentError,digits=3))%\n")
end
end
print("Mean error = $(round(mean(avE),digits=4))%, std = $(round(std(avE),digits=5))(%)\n")
Running the peeling decoder¶
- we don't have all the values in the oracle, but we have enough
# Use the patterns to create the listOfPs
# What is this?? Well basically it tells us which Pauli error fell into which bin, given our choice of experiment
# So the first vector (listOfPs[1][1])
listOfPs=[]
for p in paulisAll
hMap = []
# Because here we use right hand least significant - we just reverse the order we stored the experiments.
for i in reverse(p)
#print("Length $(length(i))\n")
if length(i) == 2
push!(hMap,twoPattern(i))
elseif length(i) == 4
push!(hMap,fourPattern([i])[1])
else # Assume a binary bit pattern
push!(hMap,[length(i)])
end
end
push!(listOfPs,hMap)
end
listOfPs
samples = []
for (ix,x) in enumerate(paulisAll)
# Similarly if we reverse above (right hand least significant, then we reverse here)
push!(samples,[[y for y in generateFromPVecSamples4N(reverse(x),d)] for d in ds])
end
samples
## This is just to remind ourselves these are the Paulis we might hope to recover
## In particular we hid a high weight Pauli with an error of 0.004, it appears below as 'number' 816
for i = 1:4096
if (dist[i]>0.0001)
print("$(string(i-1,base=2,pad=12)): $i $(dist[i])\n")
end
end
([oracleToUse[x+1] for x in samples[2][1]])
using LinearAlgebra
maxPass = 200
# singletons is when 'noise' threshold below which we declare we have found a singletons
# It will be related to the measurment accuracy and the number of bins
# Here we base it off the shotsToDo variance, on the basis of our hoped for recovery
# We start that one low and then slowly increase it, meaning we are more likely to accept
# If you have a certain probability distribution and this ansatz is not working, set it
# so that you get a reasonable number of hits in the first round.
singletons = (0.001*.999)/30000
singletonsInc = singletons/2
# Zeros is set high - we don't want to accept bins with very low numbers as they are probably just noise
# If the (sum(mean - value)^2) for all the offsets is below this number we ignore it.
# But then we lower it, meaning we are less likely to think a bin has no value in it.
# Obviously it should never be negative.
zerosC = (0.001*.999)/20000*2*1.1
zerosDec = (zerosC*0.99)/maxPass
prevFound = 0
qubitSize = 6
j6=diagm(1 => vec(hcat([[1 0] for i = 1:6]...)[1:end-1]),-1 => vec(hcat([[1 0] for i = 1:6]...)[1:end-1]))
listOfX = [[fwht_natural([oracleToUse[x+1] for x in y]) for y in s] for s in samples]
found = Dict()
rmappings = []
for x in mappings
if length(x) == 0
push!(rmappings,x)
else
ralt = Dict()
for i in keys(x)
ralt[x[i]]= i
end
push!(rmappings,ralt)
end
end
prevFound = 0
for i in 1:maxPass
for co = 1:length(listOfX)
bucketSize = length(listOfX[co][1])
for extractValue = 1:bucketSize
extracted = [x[extractValue] for x in listOfX[co]]
if !(PEEL.closeToZero(extracted,qubitSize*2,cutoff= zerosC))
(isit,bits,val) = PEEL.checkAndExtractSingleton([extracted],qubitSize*2,cutoff=singletons)
if isit
#print("$bits\n")
#pval = binaryArrayToNumber(j6*[x == '0' ? 0 : 1 for x in bits])
vval = parse(Int,bits,base=2)
#print("$bits, $vval $(round(dist[vval+1],digits=5)) and $(round(val,digits=5))\n")
PEEL.peelBack(listOfX,listOfPs,bits,val,found,ds,rmappings)
end
end
end
end
if length(found) > prevFound
prevFound = length(found)
else
singletons += singletonsInc
zerosC -=zerosDec
if (zerosC <= 0)
break
end
end
if length(found) > 0
print("Pass $i, $(length(found)) $(sum([mean(found[x]) for x in keys(found)]))\n")
if sum([mean(found[x]) for x in keys(found)]) >= 0.999995
break
end
end
end
foundV = []
print("Estimate <===> Actual\n")
print("------------------------\n")
for x in keys(found)
vval = parse(Int,x,base=2)
push!(foundV,vval+1)
print("$(probabilityLabels(vval,qubits=6)): $vval : $(round(mean(found[x]),digits=5)) <===> $(round(dist[vval+1],digits=5))\n")
end
title("Distribution of Pauli error rates")
yscale("log")
ylabel("Error Rate")
xlabel("Paulis indexed and sorted by error rate")
indices = reverse(sortperm(dist))[1:15]
scatter(1:15,[dist[x] for x in indices])
loc = [findfirst(x->x==y,indices) for y in foundV]
scatter(loc,[found[string(x-1,base=2,pad=12)] for x in foundV])
xticks(1:15,[probabilityLabels(x-1,qubits=6) for x in indices],rotation=90);

How will things improve if we up the shot count?¶
What we will see is that the accuracy of the recovery increases, but not necessarily the number recovered.¶
The recovery number after a $\delta$ of 0.25 requires we up the sub-sampling groups. This is described in the paper.
# So we kept the actual probabilities of each of the experiments
# And now we can increase the shot statistics to see how things improve:
# 1,000 sequences of 1,000 shots
manyMoreShots = 1000000
# We need culmlative probability matrixes
cumMatrix = map(cumsum,experiment1_allProbs)
experiment1_observed = shotSimulator(64,manyMoreShots,cumMatrix);
(params,l, failed) = fitTheFidelities(lengths,experiment1_observed)
experiment1_fidelities = vcat(1,[p[2] for p in params]) # We don't fit the first one, it is always 1 for CPTP maps
#Turn those into a number...
fidelitiesExtracted = []
for x0 in paulisAll[1][3]
p56 = binaryArrayToNumber(x0)
for x1 in paulisAll[1][2]
p34 = binaryArrayToNumber(x1)
for x2 in paulisAll[1][1]
p12= binaryArrayToNumber(x2)
push!(fidelitiesExtracted,p56*4^4+p34*16+p12+1) # + 1 cause we index of 1 in Julia
end
end
end
estimateOracle = [[] for _ in 1:4096]
for i in 1:64
push!(estimateOracle[fidelitiesExtracted[i]],experiment1_fidelities[i])
end
# So I am going to just do all of the above for each of the 5 (other than the one already done) for each of the qubits
e1_all_additional_fidelities = []
e1_fidelity_extracted = []
# Note we don't actually need to save the actual probabilities - but I am going to use them later
# To demonstrate some different recovery regimes.
exp_count = 1
for qubitPairOn = 1:3 # qubit pairs here are 1&2, 3&4 and 5&6
for experimentType = 1:5
if experiments[1][qubitPairOn][2] != experimentType
# Its one we haven't done
expOnFirstPair = experiments[1][1][2]
expOnSecondPair = experiments[1][2][2]
expOnThirdPair = experiments[1][3][2]
if qubitPairOn == 1
expOnFirstPair = experimentType
elseif qubitPairOn == 2
expOnSecondPair = experimentType
else
expOnThirdPair = experimentType
end
# Get the actual probabilities previously saved.
additionalExperiment = e1_all_actualProbabilities[exp_count]
exp_count +=1
# Generate the measurement statistics
cumMatrix = map(cumsum,additionalExperiment)
experiment1_additional_observed = shotSimulator(64,manyMoreShots,cumMatrix);
# Fit and extract the fidelities
(params,l, failed) = fitTheFidelities(lengths,experiment1_additional_observed)
experiment1_additional_fidelities = vcat(1,[p[2] for p in params])
push!(e1_all_additional_fidelities,experiment1_additional_fidelities)
fidelitiesExtracted=[]
for x0 in all2QlMuBs[expOnThirdPair]
p56 = binaryArrayToNumber(x0)
for x1 in all2QlMuBs[expOnSecondPair]
p34 = binaryArrayToNumber(x1)
for x2 in all2QlMuBs[expOnFirstPair]
p12= binaryArrayToNumber(x2)
push!(fidelitiesExtracted,p56*4^4+p34*16+p12+1) # + 1 cause we index of 1 in Julia
end
end
end
push!(e1_fidelity_extracted,fidelitiesExtracted)
end
end
end
# So we just need to fill in the oracle
for (expNo,x) in enumerate(e1_fidelity_extracted)
for (fidelityIndex,fidelity) in enumerate(x)
push!(estimateOracle[fidelity],e1_all_additional_fidelities[expNo][fidelityIndex])
end
end
# Generate shot limited stats
cumMatrix = map(cumsum,experiment2)
experiment2_observed = shotSimulator(64,manyMoreShots,cumMatrix);
# Fit and extract the fidelities
(params,l, failed) = fitTheFidelities(lengths,experiment2_observed)
experiment2_fidelities = vcat(1,[p[2] for p in params])
fidelitiesExtracted = []
for x1b in potentialSingles[experiments[2][4][2]] # Experiment 2, qubit division 3 (q1, q2&3, q4) the second part = exp number
p6 = binaryArrayToNumber(x1b)
for x2b in all2QlMuBs[experiments[2][3][2]]
p45 = binaryArrayToNumber(x2b)
for x2a in all2QlMuBs[experiments[2][2][2]]
p23 = binaryArrayToNumber(x2a)
for x1a in potentialSingles[experiments[2][1][2]]
p1 = binaryArrayToNumber(x1a)
push!(fidelitiesExtracted,p6*4^5+p45*4^3+p23*4^1+p1+1) # + 1 cause we index of 1 in Julia
end
end
end
end
for (fidelityIndex,fidelity) in enumerate(fidelitiesExtracted)
push!(estimateOracle[fidelity],experiment2_fidelities[fidelityIndex])
end
e2_all_additional_fidelities = []
e2_fidelity_extracted = []
# Note here I am hard coding that we have single qubit twirls on 1 and 4.
e_count = 0
exp_count = 1
for qubitOn in 1:4 # qubits we can be "On" here are 1, 2&3 4&5 and 6
if qubitOn == 2 || qubitOn == 3
noOfExperiments = 5
else
noOfExperiments = 3 # Only 3 if its a single qubit.
end
for experimentType = 1:noOfExperiments
if experiments[2][qubitOn][2] != experimentType
# Its one we haven't done
expOnFirstSet = experiments[2][1][2]
expOnSecondSet = experiments[2][2][2]
expOnThirdSet = experiments[2][3][2]
expOnFourthSet = experiments[2][4][2]
if qubitOn == 1
expOnFirstSet = experimentType
elseif qubitOn == 2
expOnSecondSet = experimentType
elseif qubitOn ==3
expOnThirdSet = experimentType
else
expOnFourthSet = experimentType
end
additionalExperiment = e2_all_actualProbabilities[exp_count]
exp_count+=1
# Generate the measurement statistics
cumMatrix = map(cumsum,additionalExperiment)
experiment2_additional_observed = shotSimulator(64,manyMoreShots,cumMatrix);
# Fit and extract the fidelities
(params,l, failed) = fitTheFidelities(lengths,experiment2_additional_observed)
experiment2_additional_fidelities = vcat(1,[p[2] for p in params])
push!(e2_all_additional_fidelities,experiment2_additional_fidelities)
fidelitiesExtracted=[]
for x1 in potentialSingles[expOnFourthSet] # Experiment 2, qubit division 3 (q1, q2&3, q4&5 q6) the second part = exp number
p6 = binaryArrayToNumber(x1)
for x2b in all2QlMuBs[expOnThirdSet]
p45 = binaryArrayToNumber(x2b)
for x2 in all2QlMuBs[expOnSecondSet]
p23 = binaryArrayToNumber(x2)
for x3 in potentialSingles[expOnFirstSet]
p1 = binaryArrayToNumber(x3)
push!(fidelitiesExtracted,p6*4^5+p45*4^3+p23*4+p1+1) # + 1 cause we index of 1 in Julia
end
end
end
end
push!(e2_fidelity_extracted,fidelitiesExtracted)
end
end
end
# So we just need to fill in the oracle
for (expNo,x) in enumerate(e2_fidelity_extracted)
for (fidelityIndex,fidelity) in enumerate(x)
push!(estimateOracle[fidelity],e2_all_additional_fidelities[expNo][fidelityIndex])
end
end
millionShotOracle = [length(x) > 0 ? mean(x) : 0 for x in estimateOracle]
using LinearAlgebra
maxPass = 200
# singletons is when 'noise' threshold below which we declare we have found a singletons
# It will be related to the measurment accuracy and the number of bins
# Here we base it off the shotsToDo variance, on the basis of our hoped for recovery
# We start that one low and then slowly increase it, meaning we are more likely to accept
# If you have a certain probability distribution and this ansatz is not working, set it
# so that you get a reasonable number of hits in the first round.
singletons = (0.001*.999)/30000
singletonsInc = singletons/2
# Zeros is set high - we don't want to accept bins with very low numbers as they are probably just noise
# If the (sum(mean - value)^2) for all the offsets is below this number we ignore it.
# But then we lower it, meaning we are less likely to think a bin has no value in it.
# Obviously it should never be negative.
zerosC = (0.01*.999)/20000*2*1.1
zerosDec = (zerosC*0.99)/maxPass
prevFound = 0
qubitSize = 6
j6=diagm(1 => vec(hcat([[1 0] for i = 1:6]...)[1:end-1]),-1 => vec(hcat([[1 0] for i = 1:6]...)[1:end-1]))
listOfX = [[fwht_natural([millionShotOracle[x+1] for x in y]) for y in s] for s in samples]
found = Dict()
rmappings = []
for x in mappings
if length(x) == 0
push!(rmappings,x)
else
ralt = Dict()
for i in keys(x)
ralt[x[i]]= i
end
push!(rmappings,ralt)
end
end
prevFound = 0
for i in 1:maxPass
for co = 1:length(listOfX)
bucketSize = length(listOfX[co][1])
for extractValue = 1:bucketSize
extracted = [x[extractValue] for x in listOfX[co]]
if !(PEEL.closeToZero(extracted,qubitSize*2,cutoff= zerosC))
(isit,bits,val) = PEEL.checkAndExtractSingleton([extracted],qubitSize*2,cutoff=singletons)
if isit
#print("$bits\n")
#pval = binaryArrayToNumber(j6*[x == '0' ? 0 : 1 for x in bits])
vval = parse(Int,bits,base=2)
#print("$bits, $vval $(round(dist[vval+1],digits=5)) and $(round(val,digits=5))\n")
PEEL.peelBack(listOfX,listOfPs,bits,val,found,ds,rmappings)
end
end
end
end
if length(found) > prevFound
prevFound = length(found)
else
singletons += singletonsInc
zerosC -=zerosDec
if (zerosC <= 0)
break
end
end
if length(found) > 0
print("Pass $i, $(length(found)) $(sum([mean(found[x]) for x in keys(found)]))\n")
if sum([mean(found[x]) for x in keys(found)]) >= 0.999995
break
end
end
end
print("Terminated finding $(length(found)) Paulis, total of $(sum([mean(found[x]) for x in keys(found)]) ) worth of probability!\n")
foundV = []
for x in keys(found)
vval = parse(Int,x,base=2)
push!(foundV,vval+1)
print("$(round(mean(found[x]),digits=6)) <===> $(round(dist[vval+1],digits=6))\n")
end
title("Distribution of Pauli error rates")
yscale("log")
ylabel("Error Rate")
xlabel("Paulis indexed and sorted by error rate")
indices = reverse(sortperm(dist))[2:15]
scatter(1:14,[dist[x] for x in indices])
loc = [findfirst(x->x==y,indices) for y in foundV]
scatter(loc,[found[string(x-1,base=2,pad=12)] for x in foundV])
xticks(1:15,[probabilityLabels(x-1,qubits=6) for x in indices],rotation=90);
